ECCV 2016 · 论文精读
Perceptual Losses
for Real-Time Style Transfer
and Super-Resolution
Justin Johnson · Alexandre Alahi · Li Fei-Fei
Stanford University
Stanford University
背景 · 两条路线
方法 · Transform + Loss Net
实验 · 风格迁移 + SR
总结 · 思想遗产
CORE NUMBER · STYLE TRANSFER
1060×
比 Gatys et al. 优化方法三个数量级加速 · 512² @ 20 FPS
CORE INSIGHT · SUPER-RESOLUTION
感知损失替代像素损失
PSNR 不再领先,但边缘 / 细节肉眼显著更清晰 · MTurk 96% 偏好
PARADIGM · 影响延续至今
GAN 损失 · LPIPS · 文生图扩散 —
"预训练网络当尺子"的范式起点
"预训练网络当尺子"的范式起点
PART 01 / 04
研究背景
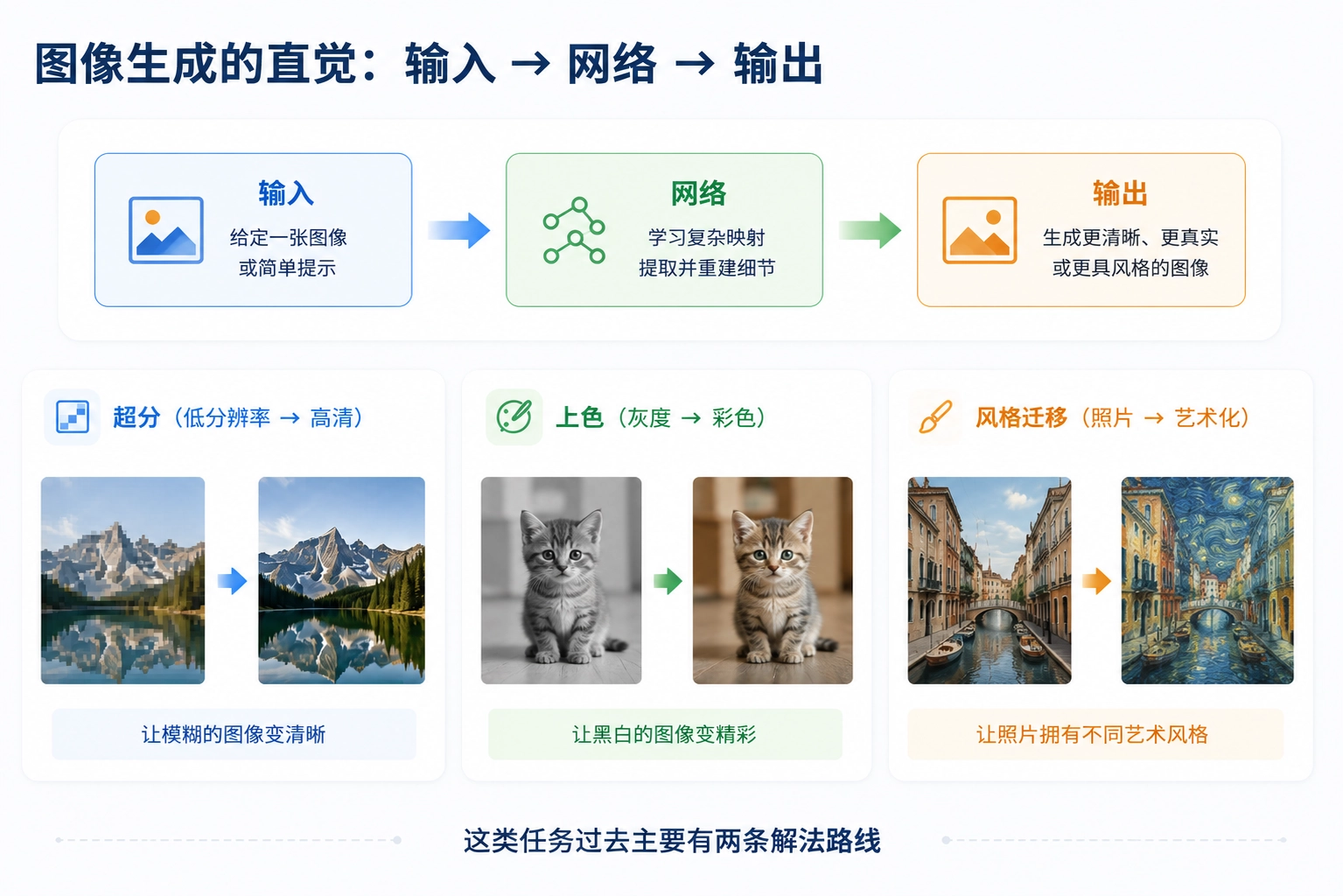
图像变换任务的两条路线 · 一边快一边美 · 谁也吃不掉对方
03
PART 1 · 背景
图像变换任务 · 输入图 → 输出图的统一框架
2016 年以前,图像变换任务主要有两条路线:一边跑得快,一边看起来好。真正卡住的是:快的路线不懂“人眼像不像”,美的路线慢到不能实时。
ROUTE A · 主流派
前馈 CNN + 像素损失
x
→
CNN · f_W
→
ŷ
vs y · L2
代表工作:SRCNN[Dong'14] 超分、Long[FCN]分割、Eigen 深度估计。
训练:per-pixel L2 / 分类损失。
推理:一次前向,毫秒级。
训练:per-pixel L2 / 分类损失。
推理:一次前向,毫秒级。
优点
推理极快 · 端到端可训练 · 易部署
致命短板 · 像素距离不等于感知距离
只差一个像素,视觉几乎相同;逐点相减却会把大量位置都算错,网络倾向输出模糊、平均化的安全答案。
ROUTE B · 优化派
迭代优化 + 感知损失
noise ŷ
→
VGG 提特征
→
迭代数百次
代表工作:Gatys[Style'15] 风格迁移、Mahendran[Inv'15] 特征反演、Simonyan 特征可视化。
训练:无网络可训 — 每张图都跑一次优化问题。
推理:分钟级。
训练:无网络可训 — 每张图都跑一次优化问题。
推理:分钟级。
优点
感知质量高 · 边缘 / 纹理 / 语义都对
致命短板 · 质量来自慢优化
100s
每张图反复更新像素,直到 VGG 特征匹配
not real-time
实时交互、视频流、批量处理都难落地
EVIDENCE A · 质量证据

SRCNN 更软、更平均;perceptual loss 保住皱褶、边界和纹理。
EVIDENCE B · 速度证据
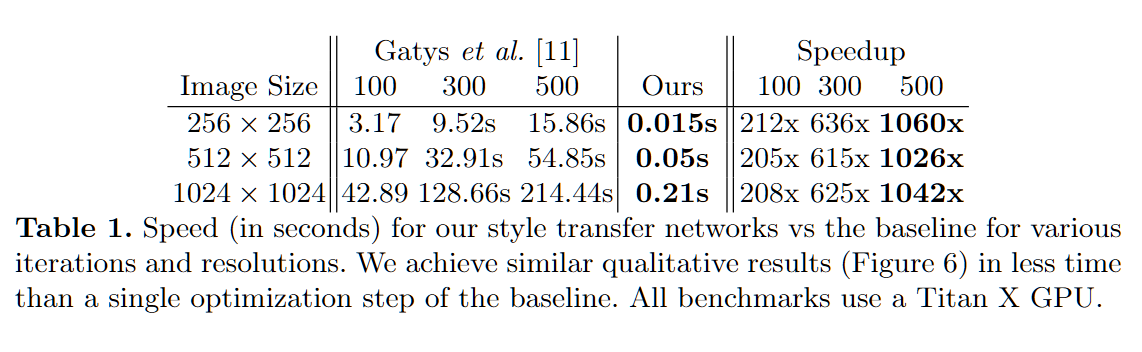
Table 1 直接给出数量级差距:本文一次前向比 Gatys 迭代优化快约 1000×。
问题自然变成:能不能既要 Route A 的一次前向速度,又要 Route B 的感知质量?
Johnson 之前的 related work 可以按三张图读:先证明 VGG 特征能比较图像,再把 内容/风格写成损失,最后借来 前馈网络的加速思路。
01
2015 · M&V
特征反演

它证明什么?
固定 CNN,优化图像像素;如果特征匹配还能反推出可辨认图像,说明这层特征保留了人能理解的结构。
留给 Johnson:用 VGG 特征差衡量“内容像不像”。
边界:不是风格迁移;也没有提出“低层=风格,高层=内容”。
02
2015 · GATYS
内容 + 风格

它补上什么?
内容用 VGG 激活对齐;风格不用像素对齐,而用 Gram 矩阵对齐通道共现统计。
留给 Johnson:内容损失 + Gram 风格损失。
代价:每张输出图都要迭代优化像素,反复跑 VGG 前向和反传。
03
2016 · D&B
前馈反演

它解决什么速度问题?
不再每次都优化一张图,而是训练一个 decoder / up-conv 网络,从表示一次前向还原图像。
留给 Johnson:慢过程可以学成快速前馈网络。
边界:它主要学重建 MSE,不是 Johnson 的感知损失训练框架。
到这里只差一步:把 Gatys 的感知目标,装进一个能前馈推理的图像变换网络。
Johnson, Alahi & Fei-Fei 的“集大成”不是重发明 VGG 或 Gram,而是把前三步接成一套训练系统:用感知损失训练前馈网络,训练完以后 推理只跑 f_W。
M&V 给它
Understanding Deep Image Representations by Inverting Them
特征重建
输出图不必逐像素相同;在 VGG 特征里像,也有意义。
Gatys 给它
A Neural Algorithm of Artistic Style
内容 + Gram 风格
高质量目标已经有了,只是原方法每张图都要慢慢优化。
D&B 给它
Inverting Visual Representations with Convolutional Networks
前馈近似
把“优化得到图像”的过程,学成一次网络前向。
图四 · Johnson 的合并答案
train: VGG loss · test: f_W only
Perceptual Losses for Real-Time Style Transfer and Super-Resolution · Fig. 1
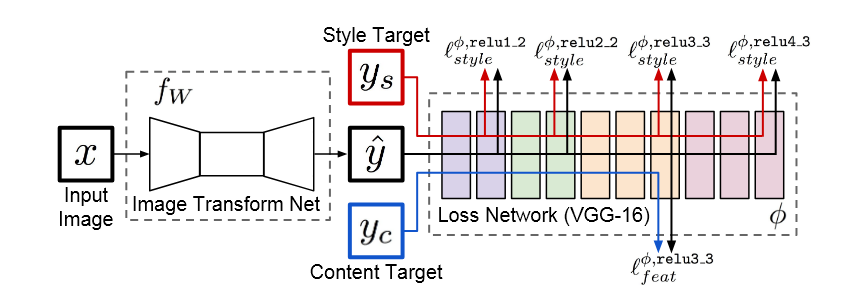
fW
只训练图像变换网络
只训练图像变换网络
φ
冻结 VGG-16 负责算损失
冻结 VGG-16 负责算损失
ys / yc
风格与内容目标分流
风格与内容目标分流
训练时
VGG 只打分
输出图和目标图都进冻结 VGG,损失的梯度穿过 VGG 回到 f_W。
推理时
VGG 被丢掉
只保留图像变换网络,一张图一次前向,所以速度来自 D&B 路线。
结果
质量目标 + 实时速度
风格迁移和超分辨率共用这条逻辑:别在像素上死磕,在感知特征上对齐。
一句话:Johnson 把 Gatys 的慢优化目标,蒸成一个训练好的前馈图像变换网络。
PART 02 / 04
方法
Transform Net + Loss Net · 两张网,一个固定一个学
Fig. 2 · 系统结构(重绘) · 左边 f_W 要训练 · 右边 φ 固定 · 风格损失取 4 层、内容损失取 relu3_3(完整目标还含 TV 正则,见后页)
① 两张网,职责分明
f_W 学着把 x 变成 ŷ;φ (VGG) 只负责"评分",是预训练的结果,全程冻结。
② 损失是一个网络
整条损失函数本身就是一段深度 CNN — 可微,所以可以反向传播。
③ 一次训练,永久部署
训练完 f_W 后丢掉 φ,推理只跑前向 — 比 Gatys 优化快 1000×。
变换网络 f_W 是全卷积深残差网络:两次 stride-2 下采样到 ¼ 分辨率 → 在 64×64 上堆 5 个残差块做最重的计算 → 两次 stride-½ 上采样还原。全卷积 ⇒ 任意分辨率都能推理。
尺寸流
3×256²
→ ↓2 →
128²
→ ↓2 →
64²
⟳ 5×RB · 128ch
→ ↑2 →
128²
→ ↑2 →
256²
→
3×256²
(↓2 蓝 · ↑2 绿,先缩后放对称)
架构图 · 风格迁移版(输入/输出 3×256×256) · 方块高度≈空间分辨率,最重计算在 64²
① 不要 Pooling · 采样可学习
上/下采样一律用 strided / fractionally-strided conv 取代 pooling,采样函数随任务一起被学。(可学习上采样的收益主要在超分,见 ⑦。)
② 中间下采样 · 两大硬核理由
同算力塞更大网:C×H×W 上做 C 个 3×3 conv ≡ DC×(H/D)×(W/D) 上做 DC 个,计算量相同。
感受野 ×2D:降采样 D 倍后每个 3×3 conv 有效感受野扩大 2D — 风格迁移要大感受野。
感受野 ×2D:降采样 D 倍后每个 3×3 conv 有效感受野扩大 2D — 风格迁移要大感受野。
③ 残差块 · 每 2 层一跳
He et al. 的 residual block:跳连每 2 个 3×3 conv 一次(out = F(x)+x),易学恒等 — 变换输出与输入共享主体结构。Johnson 沿用,但去掉相加后的 ReLU。
④ 9×9 包头包尾
首尾用 9×9 conv 更好融合 RGB↔特征;中间统一 3×3(VGG 哲学,省参、堆深)。
⑤ 末层 scaled-tanh
输出经 scaled-tanh 强制落在 [0,255],避免越界像素让训练发散 — 对比 Gatys 还要手动投影裁剪。
⑥ BN + ReLU
每个非残差 conv 后接 BN + ReLU,加速收敛、稳定深网训练。
⑦ SR 分支 · 另一个任务的变体(≠ 上面主流程)
超分输入已是低清,故不做下采样;主体同样是残差块;末端接 log₂f 个 stride-½ conv 把分辨率放大 f 倍。可学习上采样在此对比 [1] 的固定 bicubic 才是关键收益。
损失网络 φ = 在 ImageNet 上预训练的 16 层 VGG 网络,训练全程冻结。它的角色不是"做分类",而是把图像投影到一个学好的特征空间 —— 让损失在那里发生,从而度量像素之外的感知与语义差异。
经验证据 · 逐层特征重建(论文 Fig. 3)

固定一层特征 φj,让随机图反向优化去匹配它:浅层重建几乎与原图无异;越往深层,内容与空间结构被保留,但颜色、纹理、精确形状逐渐丢失。⇒ 每一层都是一把不同粒度的"尺子"。
不同层 = 不同粒度的"尺子"
| VGG 层 | 抓什么 | 论文怎么用 |
|---|---|---|
| relu1_2 | 颜色 / 边缘 | style |
| relu2_2 ★ | 细节纹理 | SR 内容损失 + style |
| relu3_3 ★ | 局部结构 | 风格迁移内容损失 + style |
| relu4_3 | 物体部件 | style |
| relu5_1 / 5_3 | 整体语义 | (过抽象, 未采用) |
★ 论文实验最终选择:
• 风格迁移 · 内容损失 → relu3_3
• 风格迁移 · 风格损失 → relu1_2 + 2_2 + 3_3 + 4_3 之和
• 超分辨率 · 内容损失 → relu2_2(更低层,保细节、抑伪影)
• 风格迁移 · 内容损失 → relu3_3
• 风格迁移 · 风格损失 → relu1_2 + 2_2 + 3_3 + 4_3 之和
• 超分辨率 · 内容损失 → relu2_2(更低层,保细节、抑伪影)
关键洞察:好的损失函数不是"发明"的,而是从分类任务里"借"来 —— 一个能在 ImageNet 上分好类的网络,必然已学到"两张图在感知上像不像"。这正是文中"借用预训练分类网络定义损失"的灵感来源(feature inversion 类工作 [7–11])。
易被忽视:φ 全程冻结 —— 梯度只回传到 fW 的权重 W,不更新 φ。这把"何谓感知相似"固定成不变的先验,训练才稳定。
Feature Reconstruction Loss 不要求像素相等,只要求VGG 第 j 层的特征图相等。它衡量的是"两张图在 VGG 眼里像不像"。
数学定义
$$\ell^{\phi,j}_{feat}(\hat y, y) = \frac{1}{C_j H_j W_j}\,\bigl\lVert \phi_j(\hat y) - \phi_j(y) \bigr\rVert_2^2$$
• $\phi_j(\cdot)$:VGG 第 $j$ 层特征图(shape $C_j \times H_j \times W_j$)
• 分母 $C_j H_j W_j$:把不同层的损失归一化到同一尺度
• 本质:在特征空间做"逐通道 L2",而不是像素空间
• 分母 $C_j H_j W_j$:把不同层的损失归一化到同一尺度
• 本质:在特征空间做"逐通道 L2",而不是像素空间
🎯 与 per-pixel 损失的关键差异
per-pixel 是 $\lVert \hat y - y \rVert_2^2$,对图像空间求和。
feature 是 $\lVert \phi_j(\hat y) - \phi_j(y) \rVert_2^2$,对特征空间求和。
⇒ 容忍像素级抖动,要求语义一致。
feature 是 $\lVert \phi_j(\hat y) - \phi_j(y) \rVert_2^2$,对特征空间求和。
⇒ 容忍像素级抖动,要求语义一致。
★ 选层 j = 选"放手程度"
上一页 Fig. 3 已直观说明后果:层越深,输出越"放飞"。
• 风格迁移要"换皮不换身" ⇒ 取中层 relu3_3
• 超分要"还原真实细节" ⇒ 取较浅 relu2_2
• 风格迁移要"换皮不换身" ⇒ 取中层 relu3_3
• 超分要"还原真实细节" ⇒ 取较浅 relu2_2
⚠ 副作用 · 网格状伪影
论文观察到:feat 模型输出在像素级出现网格状伪影,放大 Fig. 3 也能看到同样痕迹 —— 说明这源于特征重建损失本身,而非网络结构。层越深越明显,这正是超分选用 relu2_2 的直接动因。
↳ 归一化的意义
除以 $C_j H_j W_j$ 让不同层、不同尺寸特征图的损失落到同一量纲,多项加权时权重 λ 才好调。
理论根源 · 特征反演 [7] Mahendran & Vedaldi '15
[7] 让一张噪声图反向优化,直到它在某层 VGG 特征上匹配目标图,借此说明 CNN 各层"还保留了哪些可视信息"。本文反其道而行:不再对每张图慢优化,而是训练一个前馈网络 fW 去一次性产生这种图 —— 把"慢优化"蒸馏成"快前向"。
Feature loss 管"是什么内容",却抓不住颜色 / 纹理 / 笔触。Gatys 的解法:把特征图变成 Gram 矩阵 —— 一个抛弃空间位置、只保留"通道间共激活统计"的描述子。
Gram 矩阵 · 怎么构造(拉平 → 点积 → 填表)
$$G^{\phi}_j(x)_{c,c'} = \frac{1}{C_j H_j W_j} \sum_{h,w} \phi_j(x)_{h,w,c}\,\phi_j(x)_{h,w,c'}$$
$$\ell^{\phi,j}_{style}(\hat y, y) = \bigl\lVert G^{\phi}_j(\hat y) - G^{\phi}_j(y) \bigr\rVert_F^2 \qquad \ell^{\phi,J}_{style} = \sum_{j\in J}\ell^{\phi,j}_{style}$$
经验证据 · 逐层风格重建(论文 Fig. 4)

只约束 Gram 反向重建:风格特征(颜色/纹理/笔触)被保留,空间结构被丢弃;从更高层重建则迁移更大尺度的结构。
① 通道协方差 = 纹理签名
"哪些通道总是一起亮"被放大成大值 ⇒ 把笔触、配色、纹理变成可优化的统计量,与"画在哪"无关。
② 尺寸无关 · 多尺度求和
G 是 $C_j\times C_j$,与图像尺寸无关 —— 256² 训练可在更高分辨率推理;多层(1_2/2_2/3_3/4_3)求和覆盖不同尺度纹理。
★ 风格迁移 = feat + style
内容由 feat loss 锚住,风格由 style loss 替换 —— 两项相加即风格迁移目标的主体(详见下页)。
除了两个感知损失,论文还定义了两个传统的"低层"损失作为补充工具。它们简单,但在某些场景下是必要的对比基线或正则项。
① Pixel Loss · 像素损失
$$\ell_{pixel}(\hat y, y) = \frac{1}{C H W} \bigl\lVert \hat y - y \bigr\rVert_2^2$$
就是老朋友 L2。能用的前提:必须有逐像素对齐的 ground truth —— 也就是说,只能用在超分这种有真值的任务上,风格迁移没有"标准答案",无法使用。
论文中的角色:仅作为超分实验的 对照基线(ℓpixel vs. ℓfeat),不充当最终模型的主损失。
一个关键论点:PSNR 本质等价于 ℓpixel,因此用 PSNR 评测天然偏袒像素损失模型 —— 这正是论文强调"别只看 PSNR"的原因。
一个关键论点:PSNR 本质等价于 ℓpixel,因此用 PSNR 评测天然偏袒像素损失模型 —— 这正是论文强调"别只看 PSNR"的原因。
② Total Variation Regularization
$$\ell_{TV}(\hat y) = \sum_{h,w} \!\sqrt{\bigl(\hat y_{h{+}1,w} - \hat y_{h,w}\bigr)^2 + \bigl(\hat y_{h,w{+}1} - \hat y_{h,w}\bigr)^2}$$
惩罚相邻像素差异之和 — 鼓励输出空间平滑,抑制感知损失带来的高频"棋盘"伪影。
来历:沿用特征反演 [7,22] 与超分 [53,54] 的先例引入。
论文设置:风格迁移取 $\lambda_{TV} \in [10^{-6},\,10^{-4}]$,按每张风格图交叉验证各选一个值。
论文设置:风格迁移取 $\lambda_{TV} \in [10^{-6},\,10^{-4}]$,按每张风格图交叉验证各选一个值。
★ 总目标函数 · 把所有损失加权合并
$W^{*} = \arg\min_{W} \,\mathbb{E}_{x,\{y_i\}} \!\left[\sum_i \lambda_i\,\ell_i(f_W(x), y_i)\right]$
ℓ_feat
内容/语义
ℓ_style
风格/纹理
ℓ_pixel
基线对比
ℓ_TV
平滑正则
两个任务的不同配方:
• 风格迁移 = λc·ℓfeat(ŷ, yc) + λs·ℓstyle(ŷ, ys) + λTV·ℓTV — 不用 pixel loss(无真值,内容靶 yc 即输入图)
• 超分辨率 = ℓfeat(ŷ, yHR)(取 relu2_2)— 不用 style loss(无需换风格)
• 风格迁移 = λc·ℓfeat(ŷ, yc) + λs·ℓstyle(ŷ, ys) + λTV·ℓTV — 不用 pixel loss(无真值,内容靶 yc 即输入图)
• 超分辨率 = ℓfeat(ŷ, yHR)(取 relu2_2)— 不用 style loss(无需换风格)
PART 03 / 04
实验
两个任务 · 风格迁移 · 单图超分 · 一边证速度,一边证质量
风格迁移目标:复现 Gatys 的视觉质量,但把推理速度提三个数量级。训练时把"复现 Gatys 的优化结果"作为明确的可量化目标 —— 即下面这个目标函数(式 5)。
式 5 · 风格迁移的优化目标(Gatys baseline 与本文训练共用)
$$\hat{y}=\arg\min_{y}\;\lambda_c\,\ell^{\phi,j}_{feat}(y,y_c)\;+\;\lambda_s\,\ell^{\phi,J}_{style}(y,y_s)\;+\;\lambda_{TV}\,\ell_{TV}(y)$$
$\lambda_c\,\ell^{\phi,j}_{feat}$ · 内容损失
VGG-16 relu3_3 特征重建 — 让 ŷ 与原图 y_c 内容/结构一致
$\lambda_s\,\ell^{\phi,J}_{style}$ · 风格损失
relu1_2 / 2_2 / 3_3 / 4_3 四层 Gram 矩阵 — 捕捉风格图 y_s 的多尺度纹理
$\lambda_{TV}\,\ell_{TV}$ · TV 正则
全变差正则,系数 $10^{-6}\!\sim\!10^{-4}$ — 平滑图像、抑制噪点与锯齿
训练时对 MS-COCO 每张图最小化该目标的期望,把 Gatys 的逐图慢优化「蒸」成一次前向;权重 $\lambda_c,\lambda_s,\lambda_{TV}$ 与 baseline 完全一致,从而能直接对比目标值(见 P17)。
SECTION 4.1 · 数据与训练配置
| 训练集 | MS-COCO · 约 8 万张 · 256×256 |
| 优化器 | Adam |
| 学习率 | 1 × 10⁻³ |
| batch size | 4 |
| 迭代次数 | 40,000 (≈ 2 epoch) |
| 训练硬件 | 单张 GTX Titan X |
| 单风格训练时长 | ≈ 4 小时 |
| 关键约束 | 每个风格单独训一个网络 |
损失函数配置 · 核心细节
- 内容损失 (Feature Reconstruction) · VGG-16 relu3_3 特征 — 保证生成图与原图内容/结构一致
- 风格损失 (Style Reconstruction) · relu1_2 / 2_2 / 3_3 / 4_3 四层 Gram 矩阵 — 捕捉多尺度风格纹理
- TV 正则 (Total Variation) · 系数 $10^{-6}\!\sim\!10^{-4}$,每种风格图交叉验证选一个 — 平滑、减少噪点和锯齿
★ 关键设计 · 与 baseline 共享目标
训练目标 = Gatys 优化的同一个目标函数(式 5)。所以可以直接比目标值:本文网络 vs baseline 优化 N 步的结果 —— 一次训练只能学会一种风格。下一页 / 下下页给出定性 + 定量比较。
Fig. 6 / 7 是论文的"硬通货" — 把本文输出和Gatys 优化 500 步输出并排放在一起,让读者自己判断。结论:肉眼几乎区分不出,但本文快 1000×。
Fig. 6 · 256² 风格迁移结果(论文原图)
Content
Gatys [10]
Ours

顶部为风格图(The Starry Night)· 每行左→右:Content → Gatys 500 步 → 本文一次前向。Content 来自 MS-COCO 验证集,未在训练中见过。
Fig. 7 · 分辨率无关性

256² 训练的模型,直接对 512² 图像推理。全卷积 + Gram 与尺寸无关,故无需重训即可放大。
6 种 hand-picked 风格
- The Starry Night · Van Gogh
- The Muse · Picasso
- Composition VII · Kandinsky
- The Great Wave · Hokusai
- Sketch 素描 · The Simpsons 卡通
✔ 主要观察
① 内容 / 物体边界清晰保留;② 风格笔触 / 颜色 / 纹理整体复现;③ 与 Gatys 视觉差异极小。
⚠ 小瑕疵 · 重复纹理
Starry Night 等图:本文输出有些重复黄色斑块(但不相同),高分辨率时更明显。
因为本文与 baseline 优化最小化同一个目标函数,所以可以直接比较目标函数值:把"本文一次前向"和"baseline 优化 N 步"的目标值放在同一张图上。
Fig. 5 · The Muse 在三个分辨率下的目标函数值 vs L-BFGS 迭代次数(论文原图)
![Fig.5 · 目标函数 vs L-BFGS 迭代 · 256/512/1024 三分辨率 · Content / Ours / [10]](17-fig5-objective.png)
▬ Content Image(初始损失)
▬ Ours(一次前向)
▬▮▬ [10] Gatys baseline(迭代曲线)
读图方法:Y 轴是 Eq. 5 目标值(越低越好,对数刻度)。蓝色 baseline 曲线随迭代下降,与本文绿线在约 50–100 次迭代处相交。换言之,本文一次前向 ≈ baseline 优化 50–100 步,且三个分辨率结论一致。
★ 三个观察
- 本文目标值 ≈ baseline 50–100 步 — 距 baseline 收敛值 (~500 步) 只差一点
- 所有 50 张测试图结论一致 — 不是个别样本运气好
- 三种分辨率都成立 — 训练 256² → 推理 512² / 1024² 仍然有效
为什么"不到 500 步"反而够好?
baseline 50→500 步的提升主要发生在前 100 步,后面收益递减。本文用"一次前向"换"50–100 步",性价比拉满。
⚠ 客观差距
本文目标值仍略高于500 步 baseline。但下一页会看到:这点差距换来的是 1000× 加速。
Table 1 是这篇论文最有冲击力的一张表 — 直接列出本文 vs Gatys 在三种分辨率下的单图秒数。本文一次前向比 baseline 单步迭代还快。
Table 1 · 单图秒数 · Titan X GPU
| Image Size | Gatys et al. [11] | Ours | Speedup vs | ||||
|---|---|---|---|---|---|---|---|
| 100 iter | 300 iter | 500 iter | 1 forward | 100 | 300 | 500 | |
| 256 × 256 | 3.17 s | 9.52 s | 15.86 s | 0.015 s | 212× | 636× | 1060× |
| 512 × 512 | 10.97 s | 32.91 s | 54.85 s | 0.05 s | 205× | 615× | 1026× |
| 1024 × 1024 | 42.89 s | 128.66 s | 214.44 s | 0.21 s | 208× | 625× | 1042× |
红字 = 与 baseline 500 步对比的加速比(三个数量级) ·
蓝字 = 与 100 / 300 步对比 · 所有都在同一张 Titan X 上测。
★ 头条数字
1060×
256² · 与 baseline 500 步对比 — 训练一次,永久部署
实时视频可行性
20 FPS
512² @ 0.05 s/帧 → 实时风格化视频变得可能(论文核心叙事)
观察:
本文耗时 ≈ baseline 单步迭代的一半(横向对比同分辨率即可看出)— 加速比与分辨率几乎无关,恒定 ~1000×。
① 加速比恒定
256² / 512² / 1024² 三种分辨率,相对 500 步 baseline 都是 ≈ 1000×,与图像大小几乎无关。
② 成本一次付清
Gatys 每张图都要重新优化;本文把代价前移到训练,推理只剩一次前向。
③ 从"分钟"到"毫秒"
512² 由 55 s → 0.05 s:让风格迁移第一次跨入实时区间,奠定后续工作的基础。
超分是病态问题:一张低清图能对应无数张高清图,倍率越大、细节在低清里越无据可查(×4/×8 时尤甚)。本文的解法不是逐像素拟合,而是改用特征重建损失(feature reconstruction loss) —— 把预训练损失网络(VGG)的语义知识迁移给超分网络,让它学会"该补什么细节"。
Model Details · 训练参数(逐项说明)
| 损失层 | VGG-16 relu2_2 特征重建 —— 用浅层特征,保边缘细节、少失真 |
| 训练数据 | MS-COCO 1 万张图,裁成 288×288 patch |
| 超分倍率 | ×4 / ×8(更大倍率需更多语义推理,故聚焦这两档) |
| 优化器 / 学习率 | Adam · lr 1 × 10⁻³ |
| batch / 迭代 | batch 4 · 200,000 iter |
| 正则化 | 无 weight decay · 无 dropout |
| 后处理 | 直方图匹配:输出 ↔ LR 输入,校正色彩/亮度漂移 |
低清输入(LR)是怎么造出来的
HR patch
288 × 288
→
高斯模糊
σ = 1.0
→
bicubic 降采样
÷ f 倍
→
LR 输入
288/f²
训练时网络看 LR 输入、对齐 HR patch 的 VGG 特征 —— LR↔HR 成对自动生成,无需人工标注。
对照组 · 把架构差异隔离掉
与 SoTA 像素方法 SRCNN 比;并用同架构 / 同数据、只换成像素损失的 Ours (ℓ_pixel) 做对照 —— 两者唯一区别就是损失函数。
实验目的(论文原话)
不追求 SoTA 的 PSNR/SSIM,而是展示像素损失 vs 特征损失的视觉差异。PSNR 为何会"落后却更好",P22 专门拆解。
×4 是 SR 任务的主战场。论文同时给出 PSNR/SSIM 表 + 视觉对比 — 数字上本文败给 SRCNN,视觉上本文反而最好。这就是"PSNR 与人眼脱节"的实证。
Fig. 8 · ×4 超分定性对比(论文原图,每格下方为 PSNR / SSIM)

五列从左到右:Ground Truth · Bicubic · Ours (ℓ_pixel) · SRCNN · Ours (ℓ_feat)。论文点名:第一行的睫毛、第二行的帽子织纹 —— 只有 ℓ_feat 把这些细节恢复出来,但它的 PSNR/SSIM 数字却最低。
PSNR / SSIM · Set5 / Set14 / BSD100 均值 · ×4
| Method | Set5 | Set14 | BSD100 |
|---|---|---|---|
| Bicubic | 28.43 / 0.811 | 25.99 / 0.730 | 25.96 / 0.682 |
| Ours ℓ_pixel | 28.40 / 0.821 | 25.75 / 0.699 | 25.91 / 0.668 |
| SRCNN | 30.48 / 0.863 | 27.49 / 0.750 | 26.90 / 0.710 |
| Ours ℓ_feat ★ | 27.09 / 0.768 | 24.99 / 0.673 | 24.95 / 0.633 |
红色 = ℓ_feat 在数字上最差(!) · 黑加粗=最高
★ 关键洞察
ℓ_feat 的所有 PSNR/SSIM 都最差,但视觉上最锐利。这恰好说明:PSNR/SSIM 衡量的不是"看着是不是清晰",而是"是否逐像素接近 GT"。
⚠ PSNR 为何落后?
PSNR ≡ 逐像素 L2 ⇒ 用 L2 训练的模型在 PSNR 上天然占优;ℓ_feat 还会带来细密棋盘格伪影拖累分数。完整拆解 见 P21(伪影成因)/ P22(指标局限)。
×8 时 LR 已经丢掉绝大部分细节,任务退化成"猜"。SRCNN 不支持 ×8,本文只与 ℓ_pixel baseline 比 — 结果是ℓ_feat 锐化"该锐的",柔化"该柔的"。
Fig. 9 · BSD100 上 ×8 超分(论文原图,马 + 骑手)

四列:Ground Truth · Bicubic · Ours (ℓ_pixel) · Ours (ℓ_feat)。SRCNN 不支持 ×8,故只与 ℓ_pixel 对照。ℓ_feat 不是无差别锐化 —— 马腿/蹄子边界锐利,背景树木仍保持柔和。
PSNR / SSIM · ×8 · Set5 / Set14 / BSD100 均值
| Method | Set5 | Set14 | BSD100 |
|---|---|---|---|
| Bicubic | 23.80 / 0.646 | 22.37 / 0.552 | 22.11 / 0.532 |
| Ours ℓ_pixel | 24.77 / 0.686 | 23.02 / 0.579 | 22.54 / 0.553 |
| Ours ℓ_feat ★ | 23.26 / 0.706 | 21.64 / 0.584 | 21.35 / 0.547 |
ℓ_feat 的 PSNR 落后,但 SSIM 反而高(Set5 0.706 vs 0.686) — SSIM 比 PSNR 更接近感知。
★ "选择性锐化" = 语义意识
论文原句意思:ℓ_feat 锐化马的轮廓边缘,但背景树木仍保持模糊 — 这表明网络具有一定语义意识,知道"什么该锐"。
⚠ 网格 / 棋盘格伪影 · 成因(论文有专门讨论)
ℓ_feat 输出在像素级带网格状(棋盘格)伪影,拖累 PSNR/SSIM。论文判定这是特征重建损失本身的副作用,而非网络架构所致:同架构的 ℓ_pixel 伪影更少,且 Fig.3 纯优化重建也出现同样伪影。层越高 → 失真越重,故超分特意选用浅层 relu2_2 来压制。
既然 PSNR 不可信,作者直接做了人类偏好测试:在 Amazon Mechanical Turk 上把 ℓ_feat vs SRCNN 两张图并排给工人,每对图 5 人投票、全程随机化。
MTurk 偏好率
96%
BSD100 · 多数工人偏好 ℓ_feat
ℓ_feat vs SRCNN — 谁的图更好看?
测试设计:每对图给工人看一张 nearest-neighbor 上采样作参考 + 两个方法的输出,任选其一;5 人投票取多数 · 全部随机化。
为什么 PSNR / SSIM 不可信 · 论文给出 4 个证据
01
文献 [60–62] 已证明 PSNR / SSIM 与人眼主观质量相关性很差。
02
PSNR 默认残差是加性高斯噪声 —— 而超分的残差并不服从高斯。
03
PSNR ≡ ℓ_pixel ⇒ 像素损失训练的模型在 PSNR 上天然占优,不公平。
04
MTurk 真人偏好 = 数字之外的直接反例。
★ 意义远超超分本身
这是论文第一次系统地把"指标-视觉脱节"摆上台面 —— 后来的 LPIPS · FID · GAN 评估都建立在这个共识之上。
作者的克制
论文明确写:"目的不是刷 SoTA PSNR/SSIM,而是展示像素损失与感知损失的视觉差异"。
PART 04 / 04
总结
贡献清单 · 思想遗产 · 后续十年的范式起点
本文不是一个全新发明,而是把三条已有的前人贡献融合成一套系统 —— 用感知损失训练前馈网络,又快又好地解决 image transformation,并在风格迁移 + 单图超分两个任务上同时得到验证。十年后回看,它奠定了"用预训练网络当损失/尺子"的整个范式。
三大贡献的融合 → 一套可训练框架
M&V · 特征反演
特征可比
VGG 激活差能衡量"内容像不像"
Gatys · 风格
内容 + Gram
高质量感知目标,但每张图慢优化
D&B · 前馈反演
慢→快
慢优化可学成一次前向
▼ 融合
JOHNSON 2016 · 合并答案
用感知损失训练前馈网络 f_W
训练时冻结 VGG 当"阅卷老师"打分;推理时丢掉 VGG,只跑 f_W 一次前向。
验证 ① 风格迁移
1060× 加速 · 质量≈Gatys · 512² @ 20 FPS
验证 ② 单图超分
ℓ_feat > ℓ_pixel · MTurk 96% 偏好
作者展望 · Future Work
"希望把感知损失用于更多图像变换任务" —— 这一句就是后续十年视觉生成研究的 roadmap。
思想遗产 · 后续十年这条线怎么长大
2016
本文 · Johnson et al. — 感知损失 + 前馈网络,实时风格迁移 / 超分
把"预训练网络当损失"第一次系统化、可训练化
2017
Instance Norm · SRGAN / ESRGAN
IN 让风格迁移更快更稳;SRGAN 把感知损失 + 对抗损失组合,超分出真实纹理
2018
LPIPS — 把"感知距离"做成标准评测指标
正式坐实本文 P22 的论点:深度特征比 PSNR/SSIM 更贴近人眼
2019+
StyleGAN · pix2pixHD — 感知/特征损失成生成模型标配
高清图像合成普遍用 VGG 特征项约束细节
2022+
Latent Diffusion / Stable Diffusion
VAE 训练用 LPIPS 感知损失,是文生图扩散的底层组件之一
★ 一句话
"用预训练网络当尺子" —— 这个想法的所有后续,都能追回到这篇 ECCV 2016。